2025年11月18日、日本時間の20時48分頃、私たちのデジタルライフを支える重要なツールたちが突如として沈黙しました。ChatGPT、Grok、Claude、Perplexity、そしてGenspark。これら名だたる生成AIサービスが一斉に使えなくなるという、前代未聞の事態が発生したのです。「ハッキングか?」「AIの反乱か?」と不安になった方も多いのではないでしょうか。実はこの大規模障害の裏には、インターネットの「交通整理」を担うCloudflare(クラウドフレア)の深刻なトラブルが隠されていました。この記事では、あの日一体何が起きたのか、なぜ全てのAIが同時に倒れたのか、そして私たちが今後どう備えるべきかを、技術的な視点も交えつつ優しく解説していきます。

2025年11月18日、世界のAI脳が停止した日
あの日、多くの人が画面の前で「更新ボタン」を連打していたことでしょう。日本時間の夜、まさにプライムタイムに発生したこの障害は、単なるウェブサイトの閲覧不可というレベルを超え、私たちの知的活動の一部が麻痺したかのような衝撃を与えました。まずは、この「AIブラックアウト」の全貌について整理してみましょう。

日本時間20時48分、悪夢の始まりと初期症状
事の発端は、協定世界時(UTC)で11時48分、日本時間にして20時48分頃のことでした。ちょうど夕食後のリラックスタイムや、夜間の作業に集中しようとしていた時間帯です。突然、ChatGPTの画面が真っ白になり、見慣れないエラーメッセージが表示され始めました。最初は「自分のWi-Fiの調子が悪いのかな?」と思った方も多いはずです。
しかし、X(旧Twitter)を開くと、同様の報告が溢れかえっていました。「ChatGPTが繋がらない」「Claudeもダメだ」「Grokもエラーを吐いている」といった悲鳴のような投稿が、瞬く間にトレンドを埋め尽くしました。特定の一つのサービスだけでなく、これら全てのサービスが「示し合わせたように」同時にダウンしたのです。
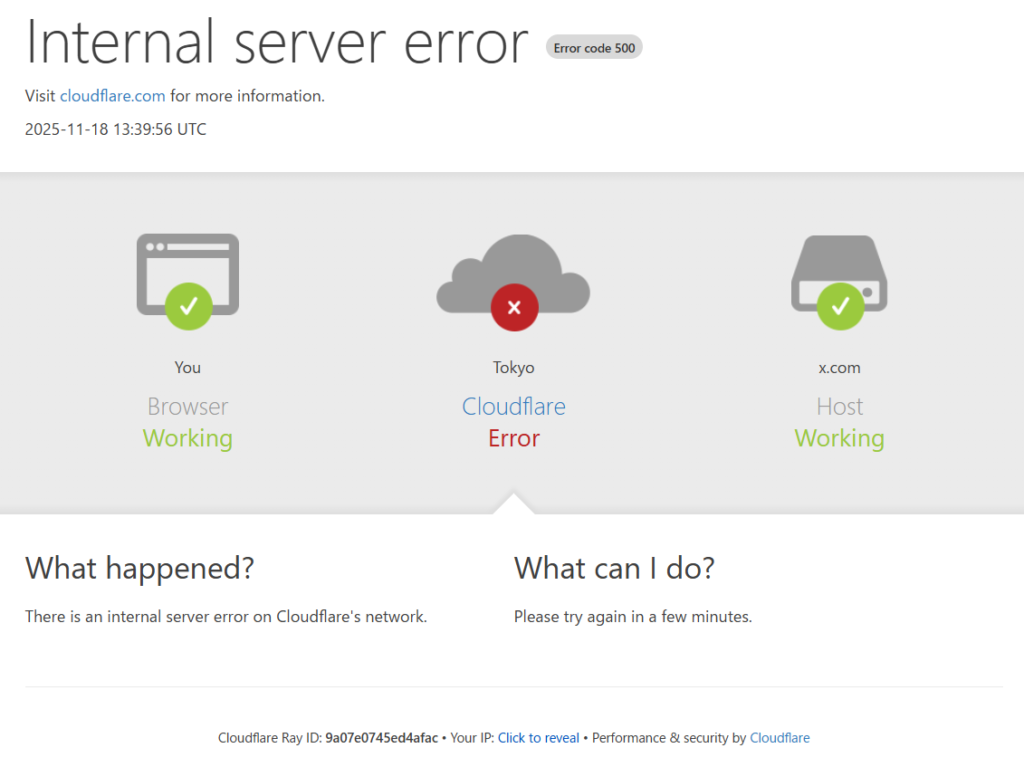
この現象は、個々の企業のサーバーが故障したのではなく、もっと根本的なインフラレベルでのトラブルであることを示唆していました。実際に、この時刻にCloudflare社が公式にインシデント(障害)を宣言しており、「広範な500エラー」が発生していることを認めています。これが、世界的なAI機能不全の幕開けでした。

「500 Internal Server Error」が意味する本当の恐怖
多くのユーザーが目にした「500 Internal Server Error」という文字列。通常、これはウェブサイト側のプログラムに何らかのミスがあった場合に表示されるエラーコードです。しかし、今回のケースにおける「500」は、普段とは少し意味合いが異なっていました。
今回の500エラーは、AI企業のサーバー(オリジンサーバー)に到達する前に、その手前にあるCloudflareのネットワーク自体がリクエストを処理しきれずにクラッシュしてしまったことを意味しています。つまり、私たちが一生懸命入力したプロンプトは、AIに届くことすらなく、インターネットの途中で「迷子」になり、消滅してしまっていたのです。

これは「502 Bad Gateway(不正なゲートウェイ)」や「504 Gateway Timeout(応答なし)」といった、相手からの返事がない場合のエラーとは明確に区別されるべきものです。Cloudflareのエッジコンピューティング環境、つまりインターネットの入り口付近で致命的な論理エラーが発生していた可能性が高く、まさに「門前払い」を食らっていた状態と言えるでしょう。
現代インターネットの「単一障害点」という脆弱性
今回の騒動で浮き彫りになったキーワード、それが「単一障害点(Single Point of Failure)」です。これは、ある一箇所が壊れるだけで、システム全体が機能しなくなってしまう弱点のことを指します。現代のインターネットにおいて、Cloudflareはまさにその巨大な一点となってしまっていました。
Cloudflareは、世界中のウェブトラフィックの大部分をさばく、いわばインターネットの「中枢神経」のような存在です。高速化のためのキャッシュ配信や、DDoS攻撃からの防御など、セキュリティとパフォーマンスの要を担っています。そのため、ChatGPTやClaudeといった最先端のAI企業も、こぞってこのインフラを利用していたのです。
しかし、その中枢神経が麻痺してしまったことで、末端にある高度なAIの頭脳も完全に孤立し、無力化してしまいました。どれだけAIモデルが優秀でも、そこに繋がる道が閉ざされてしまえば何もできません。今回の障害は、便利なサービスが一つのインフラに依存しすぎているという、現代デジタル社会の構造的な危うさを私たちに突きつけたのです。
複雑に絡み合った技術的要因と復旧までの道のり
では、具体的に何が原因でこのような大規模障害が起きたのでしょうか。調査を進めると、単なる機械の故障ではなく、定期メンテナンスと予期せぬトラフィックの急増が複雑に絡み合った「複合的な要因」が見えてきました。ここでは、その技術的な詳細を紐解いていきます。
定期メンテナンスとトラフィック急増の不運な衝突
実は障害が発生した当日、Cloudflareは北米や中南米の主要なデータセンターで定期メンテナンスを行っていました。通常、こうしたメンテナンスはユーザーに気づかれないよう、裏側でひっそりと行われるものです。しかし今回は、そのタイミングが非常に悪かった可能性があります。
以下の表は、障害発生前後にメンテナンスが行われていた主な拠点です。
| データセンター | 状況(UTC) | 影響の考察 |
|---|---|---|
| ロサンゼルス (LAX) | 10:00-14:00 進行中 | AI企業の多くが拠点を置く米国西海岸。ここの迂回処理失敗が致命的だった可能性があります。 |
| マイアミ (MIA) | 09:00開始 進行中 | 北米と中南米を結ぶ重要なゲートウェイです。 |
| アトランタ (ATL) | 障害前に予定 | インターネットエクスチェンジの主要拠点の一つです。 |
本来であれば、メンテナンス中の拠点の通信は、自動的に近くの正常な拠点へ迂回(リルート)されるはずでした。しかし、この迂回プロセスにおいて、受け皿となる他のデータセンターに負荷が集中しすぎたり、ルーティングの設定にミスが生じたりしたことで、トラフィックの「ブラックホール化(通信が吸い込まれて消える現象)」やループ現象を引き起こしたと考えられます。
復旧のために行われた「外科手術」的な遮断措置
障害発生から約1時間後のUTC 13:04(日本時間22時04分)、Cloudflareのエンジニアチームはある決断を下しました。それは、ロンドンリージョンにおけるWARP(VPNサービス)経由のアクセスを意図的に遮断するという措置です。
一見すると、さらに状況を悪化させるような対応に見えるかもしれません。しかし、これはネットワーク全体の崩壊を防ぐための緊急措置でした。異常なトラフィックの原因となっていた一部の機能を切り離すことで、システム全体の負荷を下げ、安定化を図ろうとしたのです。これを「外科的処置」と呼ぶ専門家もいます。
この措置の直後、UTC 13:09には根本原因が特定され、修正パッチの適用が始まりました。そしてUTC 13:13、ついにエラー率が低下し始め、サービスが徐々に息を吹き返し始めたのです。まるで、暴走する列車の一部を切り離して、本線を守ったかのような緊迫した対応が行われていたわけです。
ユーザーを翻弄した「フラッピング」現象
障害の最中、多くのユーザーが「あれ?繋がったかな?」と思って操作すると、またすぐにエラー画面に戻されるという体験をしたはずです。これを技術用語で「フラッピング(羽ばたき)」と呼びます。
ネットワークの状態が不安定なため、運良く正常なルートを通れば接続でき、次の瞬間に混雑したルートを通ればエラーになる、という状態が繰り返されていたのです。この間、障害状況を伝えるはずの「Downdetector(ダウンディテクター)」というサイト自体もアクセス集中でダウンしてしまい、私たちは完全に情報の暗闇に取り残されてしまいました。

このフラッピング現象は、復旧作業中にも断続的に続きました。「直った!」と喜んで作業を再開した直後にデータを失った方もいたかもしれません。完全に安定するまでは、安易に重要な作業を再開すべきではないという教訓を、私たちはこの現象から学ぶことができます。
AIサービスごとの被害状況とエラーの仕組み
今回の障害が興味深かったのは、全てのAIサービスがCloudflareを利用していたものの、その「壊れ方」には各サービスの設計思想による違いが現れていた点です。それぞれのサービスで何が起き、どのようなエラー画面が表示されたのかを詳しく見ていきましょう。
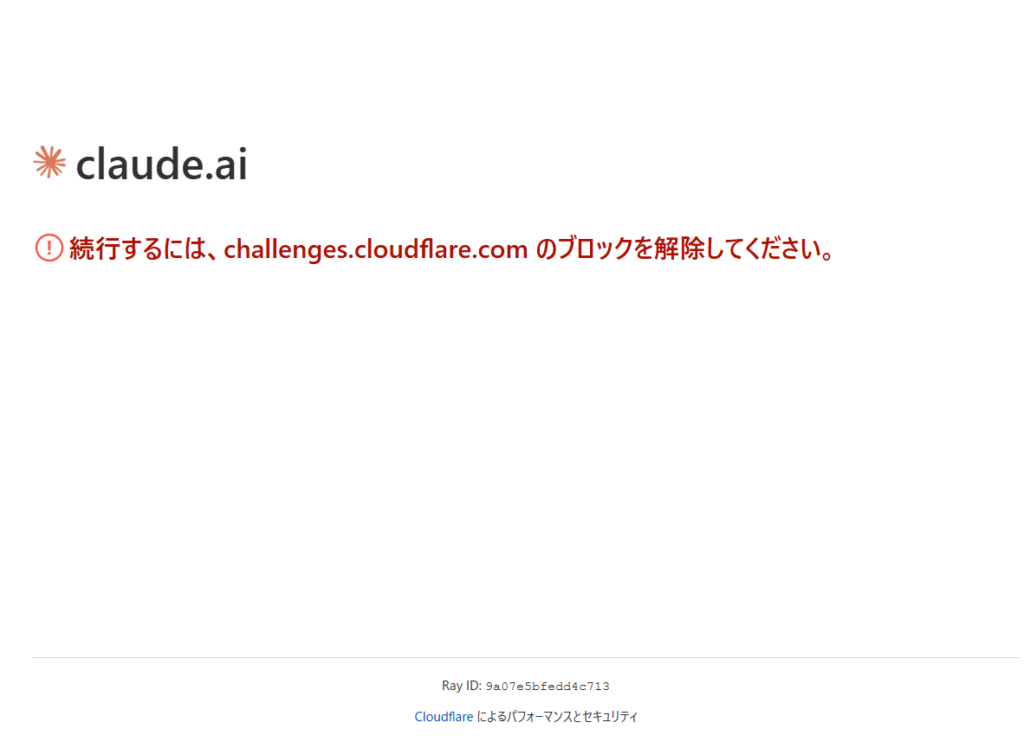
ChatGPT:無限に続く「人間確認」のループ
ChatGPTにおいて最も多くのユーザーを悩ませたのが、「Verify you are human(人間であることを確認します)」というチェックボックスの無限ループです。画面中央にCloudflareのロゴとともに表示されるこのチェックボックス。クリックしてチェックを入れても、画面が一瞬リロードされるだけで、また同じチェックボックスが亡霊のように現れました。
これは、ChatGPTのログイン画面やアクセス保護に使われている「Turnstile(ターンザイル)」というセキュリティ機能が正常に動作していなかったためです。ブラウザが「私は人間です」という証明書(トークン)を受け取ろうとしても、検証サーバー自体がダウンしているため、いつまで経っても許可が下りない状態でした。
また、仮に運良くログイン画面を突破できたとしても、今度はチャット履歴が表示されなかったり、メッセージを送っても赤いエラーバーが出たりする状態が続きました。これはバックエンドのAPIも同様に通信不能に陥っていたためで、フロントエンド(見た目)とバックエンド(中身)の両方が同時に遮断されるという、完全な機能不全状態でした。
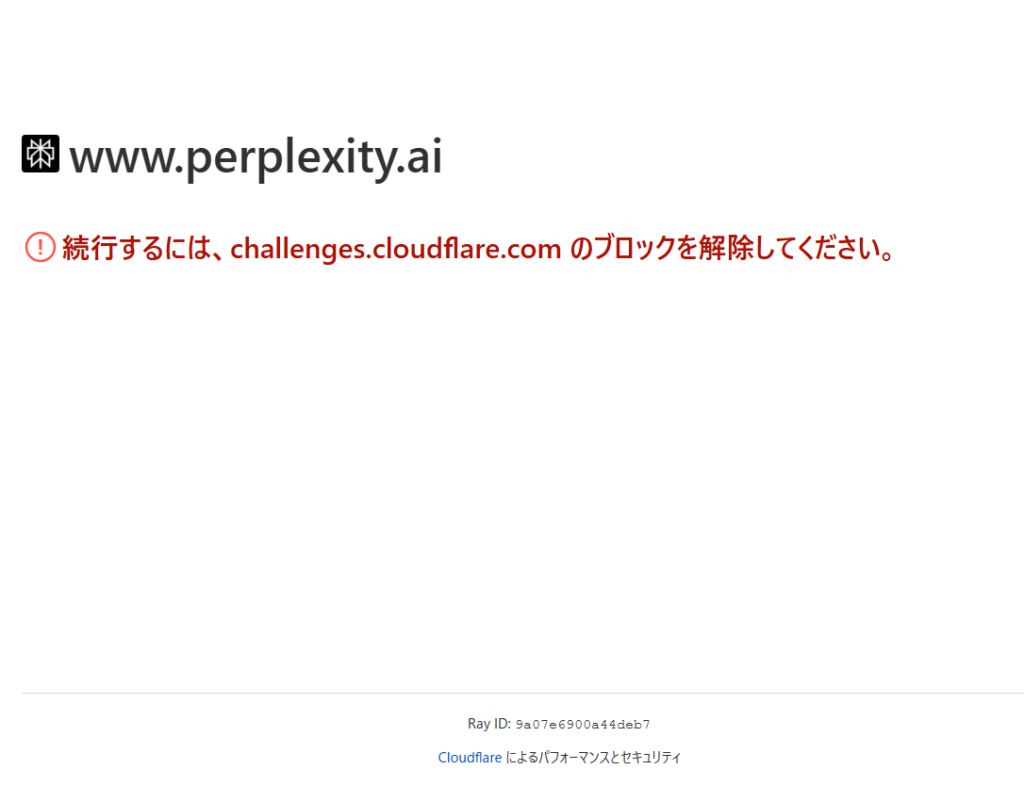
PerplexityとGenspark:検索機能が仇となった瞬間
「検索するAI」として人気のPerplexityやGensparkは、他のAIよりもさらに深刻な「二重苦」に見舞われていました。通常、これらのAIはユーザーの質問を受けると、インターネット上の情報をリアルタイムで検索し、回答を生成します。しかし、この仕組みこそが今回は仇となりました。
- ユーザーからのアクセス遮断: まず、私たちユーザーがPerplexityのサイトに繋がらない(Inboundの障害)。
- 情報収集の遮断: AIが情報を集めようと外部サイトにアクセスしても、その検索先のサイトの多くもCloudflareを使っているため、AI自身が「500エラー」を食らってしまう(Outboundの障害)。
つまり、仮に私たちがPerplexityにアクセスできたとしても、AIは「ネット上の情報が見えない、読めない」状態にあり、何も答えられなかったのです。検索拡張生成(RAG)と呼ばれるこのシステムの、意外な弱点が露呈した瞬間でした。「Something went wrong」というエラーメッセージの裏には、AIの「何も見えない!」という悲鳴が隠されていたのかもしれません。
GrokとClaude:プラットフォーム依存と誤検知の壁
X(旧Twitter)に統合されているGrokは、X自体の不具合と連動する形でダウンしました。Xも画像配信などにCloudflare系技術を利用しているため、タイムラインの画像が表示されない不具合と並行して、Grokも「Internal server error」を吐き続けました。Grokがリアルタイム情報をXの投稿から取得しようとしても、そのAPI自体がタイムアウトしてしまっていたのです。
一方、Anthropic社のClaudeは、セキュリティ重視の厳格な設計が裏目に出た可能性があります。Cloudflareの障害時には、正常な通信と攻撃のための通信の区別がつきにくくなります。Claudeの防御システム(WAF)が、普段なら通すべき正当なユーザーのアクセスを「怪しい通信」として誤検知し、ブロックしてしまった可能性があります。Claudeの画面に表示された赤字の冷たいエラーメッセージは、過剰な防衛反応の結果だったとも考えられるのです。

なぜ「私はロボットではありません」が突破できないのか

今回の障害で最もストレスフルだった「検証ループ」。クリックしてもクリックしても元の画面に戻されるこの現象は、なぜ起きたのでしょうか。その技術的なメカニズムをもう少し深掘りしてみましょう。
Cloudflare Turnstileの仕組みと破綻
私たちが普段何気なくクリックしている「人間確認」ボタン。実はこれ、裏側では非常に高度な処理が行われています。CloudflareのTurnstileは、歪んだ文字を読ませる古い方法ではなく、ブラウザの種類、画面の解像度、マウスの動きなどの「環境情報」を瞬時に分析し、人間かどうかを判定しています。
- ブラウザが情報を集めて暗号化する。
- それをCloudflareの検証サーバーに送る。
- サーバーが「OK」を出せば、通行手形(クッキー)を発行する。
今回の障害では、この「2」と「3」のプロセスが完全に破綻していました。検証サーバー自体が500エラーでダウンしていたため、ブラウザがどれだけ「私は人間です!」と叫んでも、その声は届きません。また、運良くOKが出ても、その通行手形(クッキー)が正しく保存されない、あるいはサーバー間で共有されないため、次のページに進んだ瞬間に「お前は誰だ? 通行手形を持っていないな」と門前払いを食らい、再び最初の画面に戻されるのです。
iPhoneユーザーを襲ったさらなる悲劇
特に「iPhone(Safari)で全く繋がらない」という声が多く聞かれました。これには、Apple特有のプライバシー機能が関係している可能性があります。iCloudプライベートリレーなどの機能は、ユーザーのIPアドレスを隠蔽してプライバシーを守りますが、障害発生時のCloudflare側から見ると「出所不明の怪しい通信」に見えてしまうことがあります。
さらに、Safariの強力なトラッキング防止機能(ITP)が、認証に必要なクッキーを「追跡者」と誤認してブロックしてしまい、ループ現象を悪化させた可能性も考えられます。プライバシーを守るための盾が、今回ばかりはスムーズな接続を阻む壁となってしまったのです。
ブラウザごとの挙動の違い
ChromeやEdgeを使っていたユーザーからも同様の報告がありましたが、ブラウザの設定や入れている拡張機能によっても挙動が異なりました。例えば、広告ブロッカーを入れている場合、Turnstileのスクリプト自体が読み込めずにエラーになるケースもありました。
結局のところ、この無限ループはユーザー側の操作ミスではなく、サーバー側が「認証プロセスを完了できない」状態にあったことが根本原因です。私たちがどれだけクリックを頑張っても、裏側のシステムが復旧しない限り、このループから抜け出す術はなかったのです。
日本と世界に与えた甚大な社会的インパクト
今回の障害は、単に「AIとチャットできなくて暇だった」という話では終わりません。世界中で、そして特に日本において、無視できない社会的・経済的な影響を及ぼしました。
日本の「ゴールデンタイム」を直撃した衝撃
障害発生時刻は日本時間の20時48分。多くの社会人が帰宅し、副業や学習、あるいは趣味の創作活動にAIを活用しようとしていた、まさに「ゴールデンタイム」でした。Xのトレンドには瞬く間に「Cloudflare」「鯖落ち」「ChatGPT使えない」といったワードが並びました。
日本ではインフラの安定性が非常に重視されます。普段、水道や電気が止まらないのと同じように、ネットサービスも「使えて当たり前」という感覚が根強いです。そのため、突然の利用不可に対して「アカウントがBAN(停止)されたのではないか?」「自宅の光回線が故障したのか?」とパニックになるユーザーも少なくありませんでした。この混乱は、私たちがどれだけ海外のプラットフォームに深く依存しているかを、まざまざと見せつけられる出来事でした。
開発現場と「AI依存経済」の脆さ
世界に目を向けると、欧米の一部地域では業務時間中に障害が重なりました。ここで深刻だったのは、GitHub CopilotやClaude Codeといった、プログラミング支援AIも影響を受けたことです。「AIがないとコードが書けない」、あるいは「AIがないと作業効率が半分以下になる」というエンジニアにとって、この数時間は悪夢のような時間でした。
これは「AI依存経済」の脆さを露呈させました。企業の生産性が、一社のCDNプロバイダのメンテナンスミスによって左右されてしまう現状。AI企業にとっても、有料会員に対するサービス品質保証(SLA)を守れないことは、ブランドへの信頼を損なう重大なリスクです。ユーザーの怒りの矛先は、インフラであるCloudflareだけでなく、サービスを提供しているOpenAIやAnthropicにも向かいました。
AWS障害との比較で見える「見えない恐怖」
2025年は、10月にもAWS(Amazon Web Services)の大規模障害がありましたが、今回のCloudflare障害はそれとは少し質が異なりました。AWSの障害が「サーバー(計算機)」のトラブルだったのに対し、Cloudflareは「ネットワーク(経路)」のトラブルです。
経路が断たれると、ユーザーからは「ウェブサイトそのものが存在しない」ように見えます。DNSエラーや500エラーは、サービス終了やサイト閉鎖を連想させやすく、ユーザーに与える心理的な不安がより大きいのです。「いつもの場所にアクセスできない」という恐怖は、デジタル社会における一種の遭難に近い感覚かもしれません。
私たちが取るべき「自衛策」と今後の教訓
障害はいつか必ず起きます。Cloudflareのような巨大企業であっても、ミスを完全に防ぐことはできません。では、次に同じようなことが起きたとき、私たちはどうすれば良いのでしょうか。最後に、ユーザーレベルで実践できる具体的な対策をまとめます。
「経路」を変えてみるという戦術
もし自宅のWi-FiでAIに繋がらない場合、スマホのWi-Fiをオフにして、4G/5G回線(モバイル通信)でアクセスしてみてください。これで繋がることがあります。
これは「経路」が変わるからです。自宅のプロバイダ(ISP)が使っているDNSルートと、携帯キャリアが使っているルートは異なる場合があります。モバイル回線経由であれば、障害が起きているデータセンターを回避して、正常なルートで接続できる可能性があるのです。まずは「回線を変える」、これを覚えておきましょう。
ブラウザの大掃除と「シークレットモード」
無限ループに陥ったときは、ブラウザの状態をリセットするのが有効です。まずは「シークレットモード(プライベートブラウズ)」を試してみてください。これにより、過去のキャッシュや拡張機能の影響を排除してアクセスできます。
それでもダメな場合は、ブラウザのキャッシュとクッキー(特にCloudflare関連のcf_clearanceなど)を削除します。古い認証情報が残っていると、新しい正常な通信の邪魔をすることがあるからです。また、広告ブロッカーなどの拡張機能を一時的にオフにすることも、認証スクリプトを正しく動かすために有効な手段です。
「AIは止まるもの」という前提を持つ
そして最も重要なのは、マインドセットの転換です。「AIは常に使える」という前提を捨て、「AIはいつでも止まる可能性がある」と考えておくことです。重要な業務や締め切り直前の作業において、クラウド型のAIだけに頼るのはリスクが高すぎます。
ローカル環境で動作する小規模なLLM(大規模言語モデル)を導入しておいたり、アナログなバックアップ手段を用意しておいたりすること。これが、デジタル社会を生き抜くための本当の意味での「レジリエンス(回復力)」です。今回の障害は、便利さの裏にあるリスクを再認識し、私たち自身のデジタル環境を見直す良いきっかけになったのかもしれません。
翌日の記事

ブルームバーグさまを要約すると、
2025年11月18日、Webインフラ大手であるCloudflare(クラウドフレア)のシステムに大規模な不具合が発生し、世界中のインターネットサービスが広範囲にわたってダウンする事態となりました。
この障害の影響により、OpenAIのChatGPTやX(旧Twitter)、Discord、Canvaといった主要なプラットフォームへのアクセスが一時的に遮断され、多くのユーザーが接続不能やエラーメッセージに直面しました。Cloudflare側は直ちに調査を行い、トラフィックの異常などを確認した上で修正措置を講じましたが、今回の件は同社のサービスが現代のインターネットインフラしていかに深く根付いているか、そしてその一角が崩れるだけで世界的な混乱が生じるというリスクを改めて浮き彫りになったね。ってこと。


コメント